Thanks rico, Ctrl + Enter is working just fine. I will get used to that ![]()
1 Like
Suggestion: Imagine you in a collection view and you put together a nice query with filters, projections, sort and stuff. Then you see that you will need data of different collections, therefore an aggregate based on that query but with some lookup additions.
It would be awesome to open the aggregate builder (while being in the collection view) and see that my query was converted into aggregation steps ($match, $projection and $sort) so that I just need to insert new stuff.
Maybe that’s possible to achieve with overseeable dev effort.
1 Like
Hi Hannes, this is a great idea, thank you! I’ve made a note of it for the relevant team who work with this feature.
1 Like
Suggestion: It would be awesome, really awesome, to have some kind of progress indicator when importing/exporting collection (especially imports of big collections). I never know if the import crashed (within one collection) and is running endlessly or maybe just needs more time.

1 Like
We attempt to show a progress for mongodump/mongorestore but sometimes we can’t parse the output properly. This is why your top Import is showing the “in progress and error” icon: we couldn’t parse one of the lines and we’re not sure if it’s working or not. This is obviously a bug and we try to squash all of these parsing errors. ![]()
Could you send us the status log (minus any sensitive information, of course)? Then we can figure out which line caused the issue. You can get to it like this:

The status log will look something like this:

The status log is also available for in-progress operations, so you could also use this as a workaround for seeing if the operation is stuck or not. ![]()
1 Like
-
You kind of can check the progress of a single collection import if you go into the collection that is currently importing and simply count the documents (view panel buttom right “Count documents”). This number is growing while importing and you can update whenever you want. (At least using mongodump archive restore this seems to work.) We discovered that our collection import hangs itself after 1-2 million restored documents, the import progress is still running but there are no new documents coming in.
-
Status output of the cancled import:
Thu Apr 27 10:16:01 CEST 2023: BSON Import - 2023-04-27T10:16:01.595+0200 The --db and --collection flags are deprecated for this use-case; please use --nsInclude instead, i.e. with --nsInclude=${DATABASE}.${COLLECTION}
Thu Apr 27 10:16:01 CEST 2023: BSON Import - Preparing collections to restore from
Thu Apr 27 10:16:01 CEST 2023: BSON Import - schulcloud.files - Reading metadata from archive 'C:\Users\Administrator\Desktop\Backups u Doku\JHD-45913\mongodb-schulcloud-20230406.gz'
Thu Apr 27 10:16:01 CEST 2023: BSON Import - schulcloud.files - Restoring from archive 'C:\Users\Administrator\Desktop\Backups u Doku\JHD-45913\mongodb-schulcloud-20230406.gz'
Thu Apr 27 10:21:08 CEST 2023: BSON Import - schulcloud.files - Cancelled
Thu Apr 27 10:21:08 CEST 2023: BSON Import - Done
Thu Apr 27 10:21:08 CEST 2023: Done
Thu Apr 27 10:21:08 CEST 2023: BSON Import - schulcloud.files - Done
Thu Apr 27 10:21:08 CEST 2023: BSON Import - Cancelled
2 Likes
Suggestion: On import it qould be nice to specify a query that only specific content of that backups need to be restored. Therefore I would not need to import collections with double-digit million documents.
But I assume mongorestore doesn’t support that with archive files? ![]()
1 Like
Addition to my previous post: A collegue was letting the import run and after 27mins it finished restoring. So maybe it didn’t crash and my “Count documents” trick isn’t so good.
1 Like
Unfortunately mongorestore doesn’t let you run queries on the to-be-restored documents, indeed. The best it can do is include/exclude specified databases and collections.
mongodump, however, does let you run queries - maybe you could use that to narrow down which documents are stored in the dump? ![]()
1 Like
Not an option, no. Our tech team backups entire product databases with all data (nothing else would be reasonable) but we as support only need parts of the data to respond to support cases.
My import is running since 3 hours, did not complete successfully. And thats my… 10th try, trying different combinations of import options (no validations, no indexes etc). So dependability of that import feature is… problematic. I’m currently not able to respond to that support case properly.
Any ideas what I can do to finally succeed?
1 Like
Unfortunately in the case of mongodump and mongorestore, there’s not much that Studio 3T itself does, it’s really mostly done by those two tools.
You could try running the command manually on the command line (the command can be copied from the status log, you’ll have to add the needed passwords though) and see if that’s any better. If not, this may just be a mongorestore issue. If it is better, there may be a bug in Studio 3T.
You could also try configuring a different/newer version in Preferences - MongoDB Tools. It could be that this is fixed in a newer release of mongorestore which we aren’t bundling yet (we currently bundle 100.5.4, the newest release seems to be 100.7.0).
1 Like
It’s defenitely not a Studio3T problem, I know that by now.
I’ve tried Studio3T (mongo-tools 100.5) restore in both MongoDB v5 and v6 server as well as mongo-tools 100.7 (mongorestore.exe via CMD with parameters) on v5 and v6 DB.
Command for example: mongorestore --verbose --nsInclude=schulcloud.files --drop --noIndexRestore --stopOnError --bypassDocumentValidation --archive="c:\Users\Administrator\Desktop\Backups u Doku\JHD-45913\mongodb-schulcloud-20230413.gz" --gzip --numInsertionWorkersPerCollection=1
the restore starts but halts somewhere in the process, always at a different progress:

So sometimes it restores almost 3GB (of 8GB in this collection), sometimes just 64MB, everything in between happened already. But at some point CMD just stays quiet, CTRL+C can’t interrupt the process anymore, so I need to forcefully close CMD.
mongod.log just prints
{"t":{"$date":"2023-05-12T15:02:08.560+02:00"},"s":"I", "c":"STORAGE", "id":22430, "ctx":"Checkpointer","msg":"WiredTiger message","attr":{"message":"[1683896528:559770][7284:140716900309808], WT_SESSION.checkpoint: [WT_VERB_CHECKPOINT_PROGRESS] saving checkpoint snapshot min: 72935, snapshot max: 72935 snapshot count: 0, oldest timestamp: (0, 0) , meta checkpoint timestamp: (0, 0) base write gen: 689261"}}once every minute but nothing is happening anymore, local collection gets no more new entries.
One of our techies restored this backup with mongorestore successfully (but entirely different setup with Linux and stuff).
So it has to be something in my system (1TB SSD, 64GB RAM, so the system is most probably not too weak) that causes this problem
2 Likes
Different story, back to thread topic:
I really like the new Collection History feature because it takes a step into the right (in terms of what I desire) direction.
Suggestions:
- The Collection History is kind of very hard to find. It truely is. After reading the newsletter, turning it on in pref and deleting one item I searched for the UI/button for maybe 5 full minutes. I had to go to the knowledge base and read the new “Restore deleted MongoDB documents” section to find it. Why isn’t it in the program menu (File / Edit / Database/ … / View / …)? Why isn’t there a button in the top button bar (Connect / Collection / IntelliShell …)? Or within any right-click context menu, for example on collection right click? Please make it more visible

- You have a broken link in this knowledge base article: How to Insert, Update, and Restore MongoDB Documents | Studio 3T → Article navigation → both “Managing the Collection History” and “Restore deleted MongoDB documents” are not yet linked.
- Currently the history only recieves items that were deleted manually, by hand, right? It would be awesome if deletion via IntelliShell (script with deleteMany or so) and Aggregates (aggregate with $unset) would also result in a local backup. This would complete a real deletion history, currently it’s a bit limited. Most of our deletions are done by scripts or aggregates, “one does not simply delete items by hand in production” (<- possible meme… yeah, meme time!)
(yeah, it’s Friday, there’s a minute of free time for bullshitting around ) - Please expand this feature to hold edits as well. 90% of the stuff done is edit, not delete. It would be nice to be able to redo these as well. Like in 3.) including script stuff.

Keep up the good work!
2 Likes
Hi Hannes!
I’ve passed this feedback to our team who built this feature. We really appreciate these valuable comments. We’ll look into how to improve the experience of finding the Collection History for a start. Deletion via IntelliShell or Aggregation isn’t something we were considering currently, but we will certainly discuss it nonetheless. Adding Edits to this feature is in the pipeline already so we look forward to hearing your review of this once it becomes available in future ![]()
1 Like
Maybe I’m missing a feature and just doin’ it wrong. Otherwise:
Suggestion: It would be good to be able to use file-based input data in IntelliShell scripts. We often get big csv data files and have to check/modify/create/delete data in our databases based on the given data. If Studio could “load” a csv file and make it accessible in IntelliShell via a variable, that would be awesome.
What we currently do: Either by hand edit CSV as text to form a valid multi-level array to copy directly into the IntelliShell script which uses this array. Or put csv lines as text into IntelliShell and split it there. Both ways do have stumbling blocks and problems, depending on the values/texts inside.
I’m afraid I can’t share CSV content but maybe this helps to understand our current way how to handle it (one of the two above ways):

(for example this simple thing won’t work if our csv would have content that contains the csv delemiter “;” itself as normal text - the split would have to be way more complex to handle the file then)
I think one of the numerous CSV-parsers as a built-in Studio feature would do a better job and maybe the fields/values would get accessible in a nicer way than “var” without having to code it myself in every script.
1 Like
Good suggestion, that might be worth an investigation! ![]()
Here’s something to tide you over though: mongosh is built on top of Node.js, so you can also require external modules (although they need to be installed first), which should then allow you to parse the CSV file “the Node.js way”: node.js - Parsing a CSV file using NodeJS - Stack Overflow
2 Likes
Suggestions:
- Connect to multiple connections “at the same time” (I mean selecting 6 connections → right click → connect). Currently you can only connect one single connection, open connection manager again, scroll down to where the next server is, connect next and so on.
- Use Pagaent to auth with SSH key instead of managing that for each and every connection. Like WinSCP does it: Using Pageant for Authentication :: WinSCP
(or maybe Studio can do that and I didn’t know how)
2 Likes
The first suggestion already has a ticket, but I can’t promise a release date (yet). ![]()
The second point has been under consideration for a long time, with an even more generic approach in that we would just let the user supply a command to establish the SSH tunnel. Unfortunately this won’t be ready for a while, I’m afraid, but it’s definitely still on our radar.
2 Likes
It’s been a while! ![]()
You know, in this thread I’m bitching a lot, but don’t get me wrong here: Studio3T is awesome, works very well, does have tons of features and is an invaluable working tool. I just want you to imporve even further! ![]()
With that in mind, here are some things that built-up in the last months, I just coulnd’t find enough free time to write it down. Until now.
-
IntelliShell problem: Print adds two(!) new lines (1. go to new line 2. add blank line) after the specified output. Multiple prints without blank line in between only possible with one print + multiple \n chained or workaround: Shell Output avoid new lines - #5 by SchurigH
But if you look at my 6th point regarding switch case - there all prints come without newline at all… wtf?! Just noticed that. -
IntelliShell suggestions: There is a cool feature here: “Run selection (F9)” - it’s nice to test parts of a bigger script this way instead copy pasting everytime into different IntelliShell instances. BUT: If I’m using variables (which I do, of course), I always have to copy paste all variables right before the tested part to also select these. Otherwise the code won’t work. It would be nice to either be able to set global IntelliShell variables or keep variable values between runs.

- Global variables for a single IntelliShell tab and kind of super-global (…) variables for all IntelliShell tabs. You would set these up in some setting dialog, apart from the code and use them in the code.
- Or there is a mode in which an IntelliShell script tab saves variable values between different runs. So I run all code before my testing part, variables get all their values, after that I could execute my code lines seperately and all variables would still have their values of the last run(s). Such setting might be worth auto-disabling for each newly opened IntelliShell tab because this type of variable behaviour would be very unusual and result in errors of not used purposely.

-
Visual Query Builder problem: One of my first reported problems still exist: The yellow popup on ObjectID-Drag&Drop actions: My Suggestions / Bugs Thread - it still annoys me.
-
IntelliShell error detection seems broken:
console.log("test")
/db.getCollection("users").updateMany({ schoolId: fromSchool }, { $unset: { roles: "" } })
db.getCollections("users").updateMany({ schoolId: toSchool }, { $unset: { roles: "" } })
contains three errors: Slash in front of line 2, “getCollections” in line 3 and unknown variables in these lines. No errors detected by IntelliShell. Same for a coworker with this code. Console.log can also be print(..), same result.
If I remove line 1, the slash as 1 error is detected, no other errors. If I then remove the slash, no errors are detected but run the code and
Uncaught
ReferenceError: fromSchool is not defined
Uncaught
TypeError: db.getCollections is not a function
will be the output. If you take my example code from above and put a “;” at the end of console.log, everything will be an error.
I have bigger scripts where no errors are detected anymore even if there are dozens.
-
It is not possible to save a new IntelliShell script as an existing one (and overwrite that). To work around you can manually enter the name of an existing script into “Script name”, it will recognize it correctly. After that has been saved once, you can select existing scripts and overwrite them as you would expect it to.
-
Switch case break won’t work in IntelliShell scripts? Switch will not enter all cases but once its in a case, it will not exit the switch on break as you would expect:


More stuff will come tomorrow.
1 Like
Alright, let’s continue:
- Let’s start with some positive feedback:
- Opening an existing collection tab also selects/highlights this collection in the “Open connections” sidebar.
- Writing scripts with active errors is much more performant now. A few months back IntelliShell was super slow when typing in a script with errors present.
- The “Edit document (as JSON)” / Document JSON Editor dialog/popup can now be in the background, so you can handle other things, copy data from somewhere else, while having this open. A few months ago I struggled with this because I had to collect all data needed beforehand.
- Resizing this Document JSON Editor window is being saved! (At least until next Studio restart I think)
-
Talking about this Document JSON Editor… Go to a document in JSON View, select some content from it (no matter what) and press Strg+J → JSON Editor opens and your selection is kept / selected again
 … BUT: Now select smth in JSON View, rightclick on it → Document → Edit Document (as JSON)… → same dialog, no selection pre-made
… BUT: Now select smth in JSON View, rightclick on it → Document → Edit Document (as JSON)… → same dialog, no selection pre-made 
-
Talking about JSON view… Most of my time I’m using table view, lot’s of data analysed with one blink of the eye. But for some deep nested stuff I go to JSON view, again lot’s of data with one blink of the eye, but more complicated. If I then open a new collection tab, this JSON view is kept. I know, it’s somehow consistent to keep the last view but in this case it’s no good. I almost can’t think of any useful reason to look at an entire collection as JSON view, that seems not useful. Maybe add a “default view for new collection tabs” setting where I can set table view as default and it always opens that way? I’m fine with a “last used view” option within that setting that keeps the current behaviour.
-
Talking about UI functionality: Export → CSV → will scan your export data for fields and display them to select/unselect and… … to sort it. But no, this is not possible to be honest:
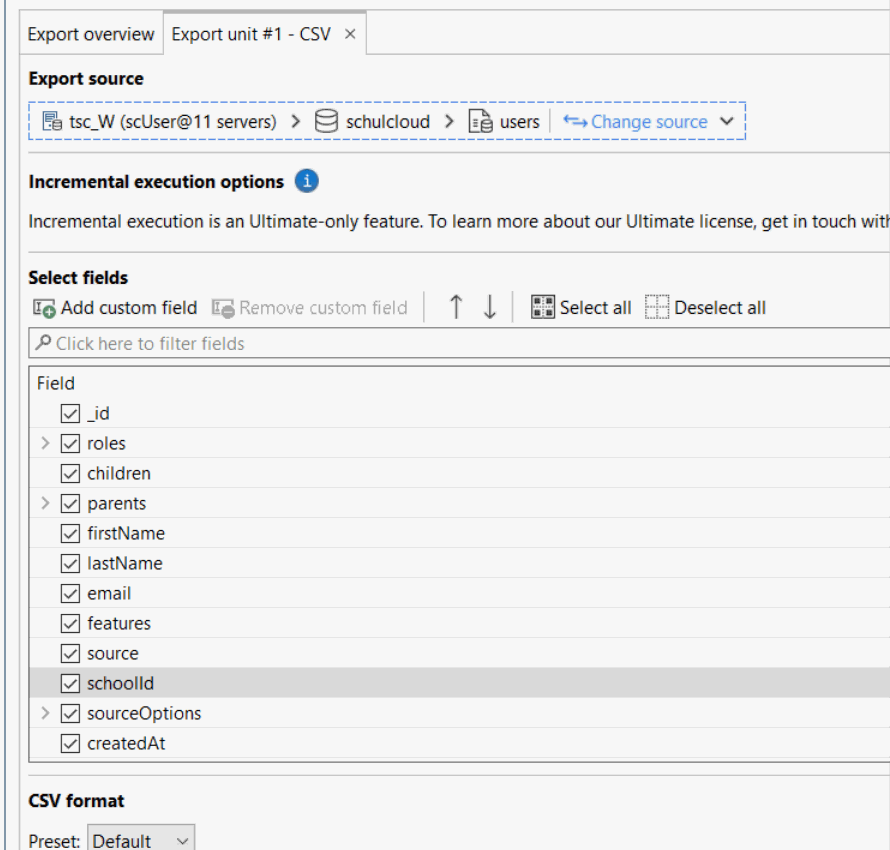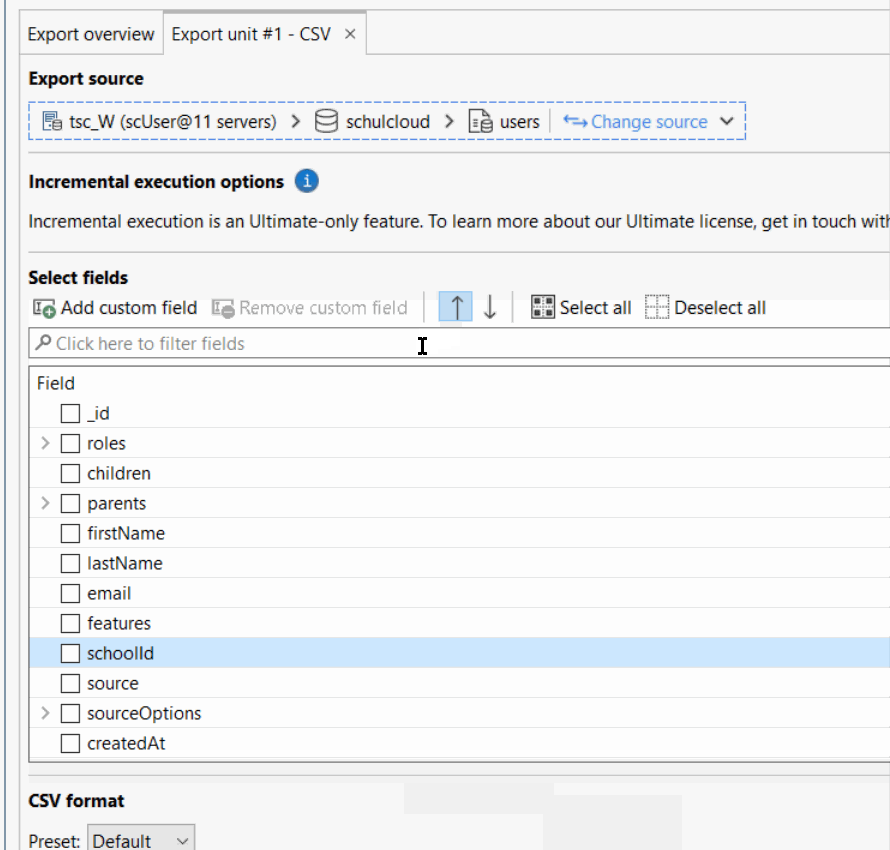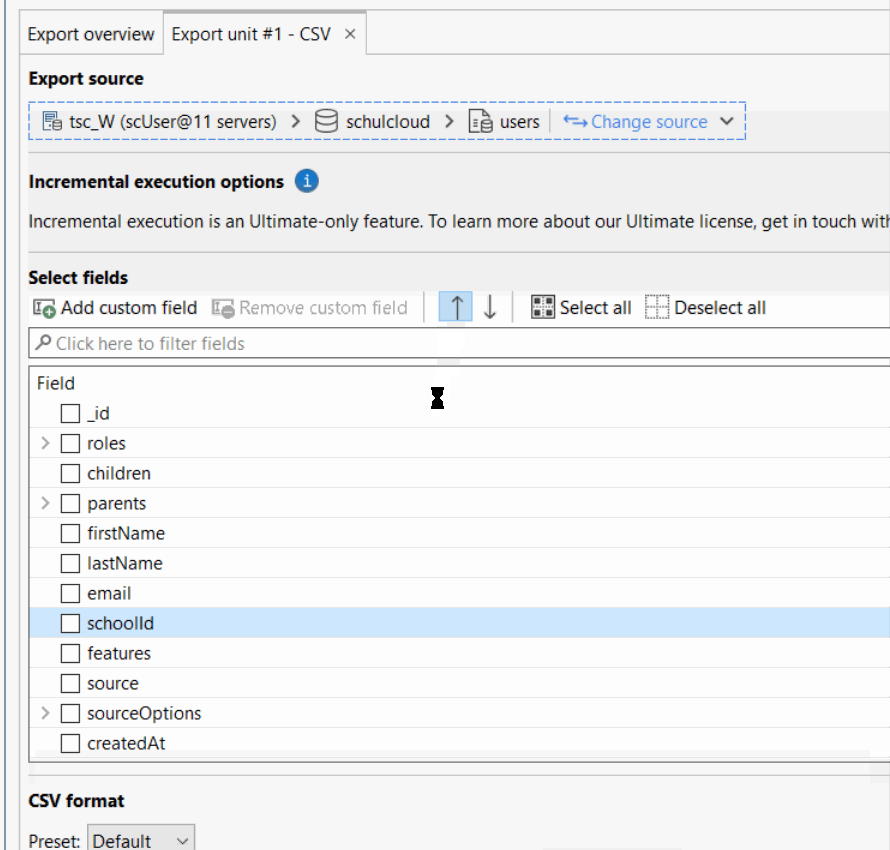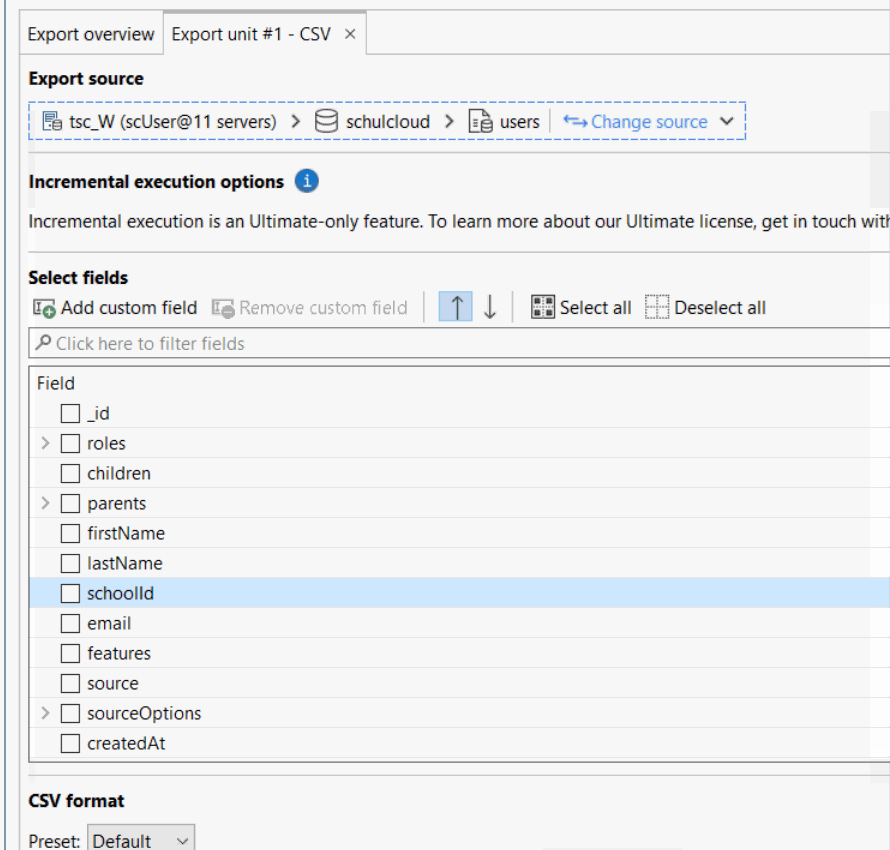
… I’m laughing so hard just how bad this is. There is no drag&drop, there is no “move to the top/bottom” and moving a field just 1 time takes like 8 seconds. No, this is not usable and it’s sad because we work massively with CSV exports for our customers. Please, Studio3T can really do better than that
-
Talking about functionality (
 ): I wish for a “re-open last closed tab” feature, set to Strg+Shift+T (just like in all browsers this reopens the last tab), open Tasks (currently this shortcut) can go away!
): I wish for a “re-open last closed tab” feature, set to Strg+Shift+T (just like in all browsers this reopens the last tab), open Tasks (currently this shortcut) can go away! 
It would be nice to re-open the last closed tab with all it’s settings/queries, maybe even the page that you were on. Maybe it would also re-open IntelliShell tabs even with unsaved script code in it - just like Studio3T boot-up does it when it opens all previously opened tabs. -
I mentioned that in another topic I think: It would be nice if Import data → BSON - mongodump archive → was able to import multiple collection with the “import data only for collection” option. Currently (last time I checked) there can only be one collection and if you want to import 10 out of 40 collections of a database backup, this gets tedious. I know that this is some kind of mongorestore command restriction but Studio as UI could also chain multiple mongorestore commands for every collection after another to allow such feature.

So… that feels good enough for now.
I wish you all a very successful new year, stay healthy and motivated, all the best!
Hannes
1 Like